La classification d’images devient une tâche plutôt courante dans le monde dans la Data Science, et les méthodes permettant d’y parvenir sont relativement établies.
Cette tâche s’inscrit pourtant dans un domaine plus vaste, la Computer Vision, où l’objectif est d’analyser et d’exploiter les informations contenues dans une image ou une vidéo par exemple.
Des exemples pratiques parmi les plus connus :
- la détection de personnes via une caméra de surveillance
- la détection et l’estimation de la dangerosité de tumeurs sur des radiographies
- la reconnaissance automatique d’écritures manuscrites sur des formulaires
Ces cas d’application ont vu leur efficacité largement augmenter depuis 2012 via l’adoption des méthodes de Deep Learning.
Un des aspects clés est le fait de pouvoir traiter des images brutes directement, c’est-à-dire avec pas ou peu de prétraitement humain en amont. Ce point en particulier permet d’appliquer plus facilement les méthodes de Deep Learning à une grande multitude de tâches et de métiers différents.
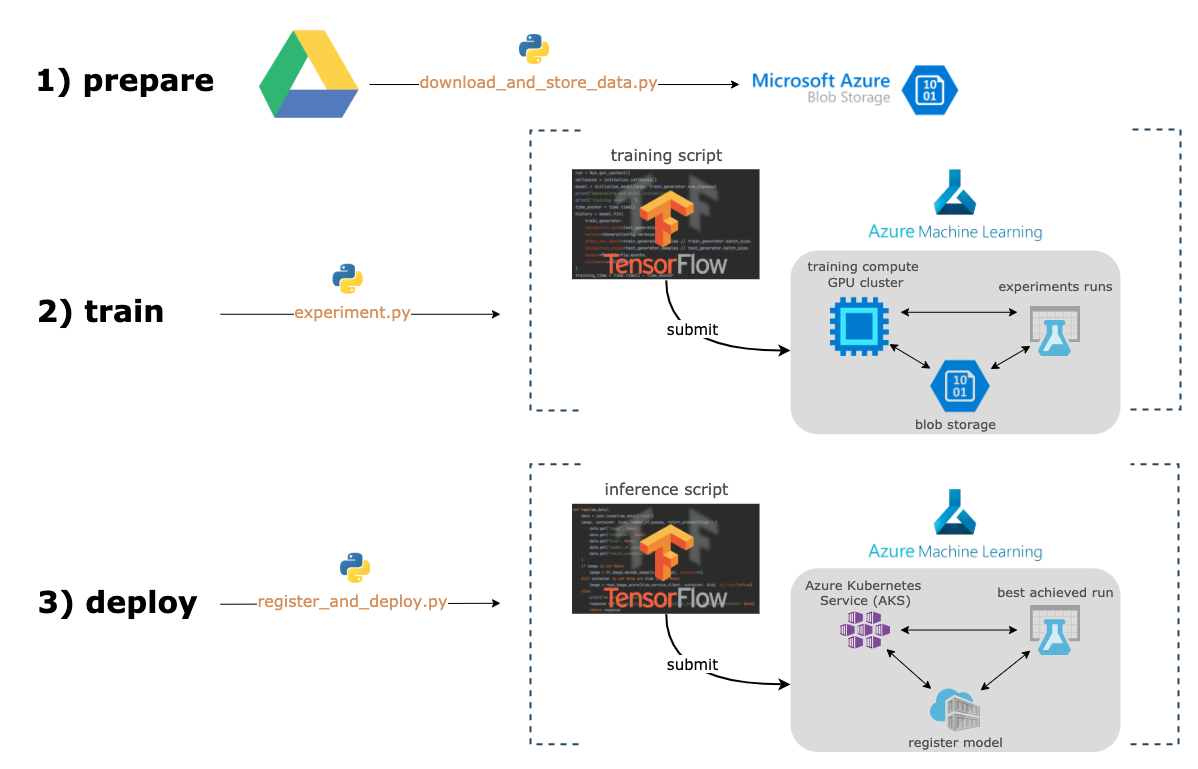
Nous allons ici présenter un cas d’application concret de bout en bout : la classification automatique de plats via leurs photographies.
Ce projet est suffisamment générique pour pouvoir être réadapté à une grande variété de projets de classification d’images.